22 de septiembre de 2021

En nombre del Grupo de Trabajo de Bancos y Seguros de XBRL Europe, me gustaría presentar nuestro trabajo hasta ahora sobre cómo se puede utilizar el formato xBRL-CSV para manejar datos granulares, dentro de un enfoque de informes cada vez más integrado. Nuestra prueba de concepto sugiere que xBRL-CSV podría agilizar el proceso de presentación de informes y facilitar a los usuarios la comparación y el análisis de información de diferentes países y los requisitos de presentación de informes, incluidos datos extensos y detallados.
Queríamos ver una iniciativa de informes existente que es conocida por producir grandes volúmenes de datos y, por lo tanto, tomamos AnaCredit como nuestro ejemplo. AnaCredit, que significa ‘conjuntos de datos analíticos de crédito’, es un proyecto del Banco Central Europeo (BCE) que requiere la presentación de información detallada sobre préstamos bancarios individuales en toda la zona del euro. Como era de esperar, esto representa una gran cantidad de datos.
AnaCredit se lanzó en 2011, aunque las primeras presentaciones no se realizaron hasta 2018. Incluso al principio, estábamos interesados en usar AnaCredit como un caso de estudio, pero en ese momento no teníamos las herramientas de modelado de puntos de datos (DPM) que tenemos hoy, y ni siquiera se pensó en xBRL-CSV. Por lo tanto, era demasiado pronto para adaptar AnaCredit a XBRL, pero ahora tenemos capacidades muy diferentes a nuestra disposición. Nuestro objetivo no es efectuar un cambio en los informes de AnaCredit, sino usarlo como un ejemplo de cómo podemos manejar esta cantidad de datos y probarlos con nuestros procesos.
Modelo de puntos de datos para conectar datos con significado
Nuestro primer paso fue capturar las definiciones utilizadas para AnaCredit. Una de las dificultades que enfrentamos fue que estas definiciones no son exactamente las mismas en todas partes, ya que cada país ha decidido diferentes procesos de presentación de informes. Eso significa que, para los proveedores de software, trabajar en AnaCredit en toda Europa es una pesadilla porque las reglas cambian de un país a otro.
Nuestra solución fue aplicar un modelo de puntos de datos a los datos y las reglas de archivo adjuntas. Un DPM conecta la plantilla de informes legible por humanos con las definiciones técnicas en la taxonomía XBRL, dando a los conceptos de informes significados legibles por máquina.
Figura 1: Plantilla de informes de AnaCredit para el conjunto de datos de ‘Datos de referencia de la contraparte
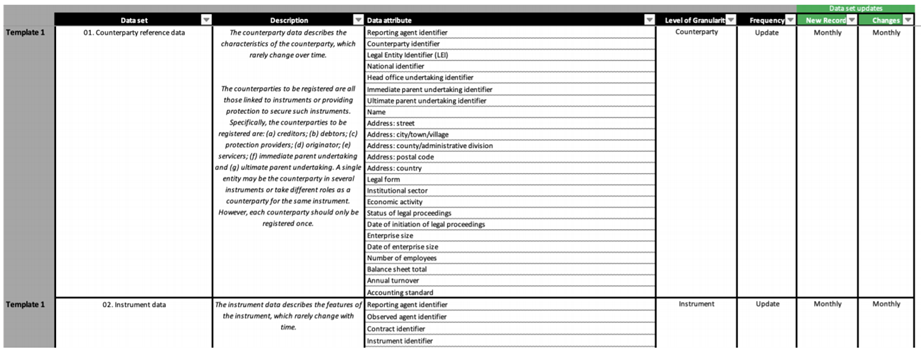
La Figura 1, por ejemplo, muestra la plantilla de informes de AnaCredit para ‘Datos de referencia de la contraparte’, con una lista de campos para que los utilicen los declarantes. Nuestra tarea consistía en identificar los datos y crear conceptos para cada hecho o, idealmente, tomar conceptos existentes utilizados en otros informes, por ejemplo, por la Autoridad Bancaria Europea (EBA).
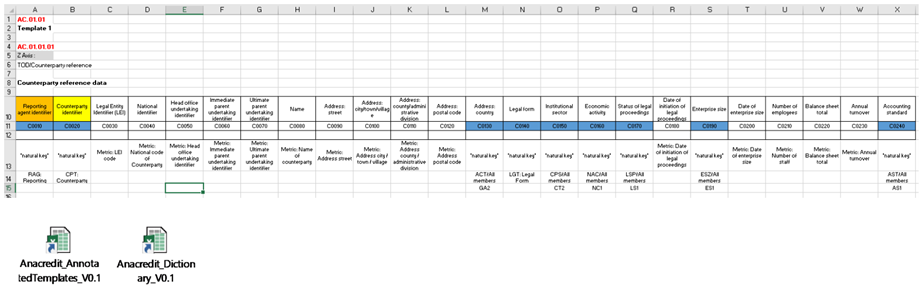
La Figura 2 muestra los requisitos de presentación de informes de datos de referencia de la contraparte convertidos en el DPM, produciendo una plantilla anotada en formato de tabla. También viene con un diccionario de definiciones de conceptos y sus orígenes. Esto combina conceptos específicos que desarrollamos para AnaCredit con conceptos importados de EBA, como la definición del código de Identificador de Entidad Legal (LEI), que ya está implementado en los informes de EBA.
Figura 2: Tabla DPM para datos de referencia de la contraparte.
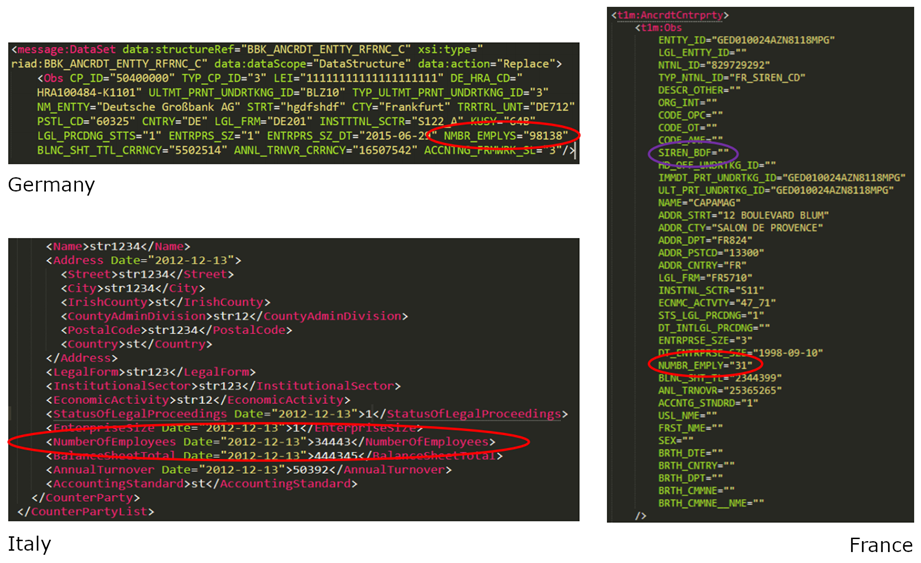
Una de las complicaciones es que la forma en que se informan los datos de Anacredit varía considerablemente de un país a otro. La Figura 3 muestra algunos ejemplos tomados de informes digitales reales de diferentes países. Podemos ver que si tomamos el elemento ‘Número de empleados’ (encerrado en un círculo en rojo), en Alemania este concepto se denomina «NMBR_EMPLYS», en Francia «NUMBR_EMPLY» y en Italia «Número de empleados». El DPM nos permite vincular con éxito todos estos al concepto subyacente.
Si bien todos estos países utilizan XML para la presentación de informes, la estructura del código es muy diferente. Por último, algunos países también tienen requisitos adicionales de presentación de informes nacionales, reflejados en campos adicionales. Por ejemplo, en Francia, los contribuyentes también deben informar el SIREN, un identificador nacional, para cada contraparte (encerrado en un círculo en violeta). El objetivo del grupo de trabajo era ver cómo se podían abordar estos problemas.
Figura 3: Ejemplos de diferencias en los informes de Anacredit entre países.
Ventajas de XBRL
El beneficio más importante que aporta XBRL es la estandarización de datos. El diccionario y los conceptos compartidos guían a los declarantes sobre cómo informar correctamente cada hecho y garantizar que los datos sean comparables. Es importante destacar que los datos se generan y consumen fácilmente mediante el uso de herramientas XBRL conocidas, que ya están disponibles para los informes actuales en la mayoría de los bancos y autoridades nacionales competentes (NCA) en toda Europa.
XBRL también proporciona extensibilidad. Los países o reguladores individuales pueden ampliar la taxonomía para agregar campos específicos para capturar sus propios requisitos de informes. Banque de France, por ejemplo, agrega campos adicionales a la plantilla de informes del Fondo de Pensiones Europeo. Con XBRL, estos se manejan fácilmente y los datos adicionales se filtran antes de enviarlos a la Autoridad Europea de Seguros y Pensiones de Jubilación (EIOPA). En otras palabras, XBRL nos brinda una forma estándar de agregar campos personalizados según sea necesario, sin afectar la integridad de los informes compartidos principales. Al mismo tiempo, la capacidad de reutilizar conceptos existentes ayuda a facilitar la comparación y el análisis de datos de diferentes informes.
La Figura 4 muestra una visualización fácil de usar de algunas líneas de un informe de AnaCredit XBRL, que se muestra como se especifica en nuestra taxonomía de prueba de concepto. Una herramienta XBRL estándar puede producir esta visualización utilizando información incrustada en el paquete de informes. Otra ventaja de XBRL es la capacidad de los usuarios para determinar cómo se presentan los datos digitales, posiblemente utilizando plantillas diferentes o modificadas. De particular interés en la Europa políglota es el potencial para integrar de forma nativa varios idiomas para mostrar las etiquetas y los conceptos de las tablas, y permitir que los espectadores cambien automáticamente de un idioma a otro. Esto ya se está haciendo para los informes de la Junta de resolución única (JUR), por ejemplo, cuando la taxonomía está disponible en diferentes idiomas.
Figura 4: Visualización de un informe de AnaCredit XBRL utilizando la presentación especificada en la taxonomía.

El último, pero no menos importante, beneficio clave de XBRL es el potencial de validación para verificar datos, detectar problemas y mejorar la calidad. Las reglas de validación se pueden definir e implementar de forma nativa para ejecutarse en herramientas XBRL estándar. Los resultados de la validación dependen de los niveles de precisión establecidos para los datos; la capacidad de ajustarlos agrega sensibilidad a los controles de validación.
Ventajas de xBRL-CSV
Además de los beneficios generales de XBRL, la ventaja adicional más importante de xBRL-CSV es que produce archivos mucho más pequeños, lo que hace que los informes sean mucho más fáciles de producir, manejar, enviar y almacenar. La Figura 5 muestra una comparación de dos informes, con los mismos datos capturados en formato XBRL 2.1 tradicional basado en XML y en formatos xBRL-CSV. Incluso sin una gran cantidad de conocimientos técnicos, está claro que en el informe XML los metadatos ocupan mucho espacio y los datos reportados, que se muestran en blanco, son solo una fracción del contenido del código. Los datos en xBRL-CSV son notablemente más compactos.
En general, el uso de xBRL-CSV para los datos de AnaCredit reduce el tamaño del archivo en casi un factor de diez, en una proporción lineal. Por ejemplo, una tabla con 300.000 filas produce un archivo de 62 Mb en xBRL-CSV y un archivo de 574 Mb en XBRL 2.1. Para una tabla con 3.000.000 de filas, esos números son 622 Mb y 5.744 Mb respectivamente.

Los archivos xBRL-CSV también se pueden leer y editar fácilmente. Todos los datos están contenidos en un archivo o archivos CSV simples, mientras que los metadatos se definen en un archivo JSON separado muy pequeño, al igual que las propiedades de la tabla. Esto facilita que los contribuyentes y otros usuarios se concentren en los datos; Es muy sencillo acceder a datos específicos y editar los archivos CSV sin conocimiento de XBRL, utilizando herramientas conocidas y generalizadas. Este rápido acceso a los datos también facilita potencialmente el proceso de validación.
Una base para la experimentación
Esta prueba de concepto nos brinda una buena base para prepararnos para informes integrados de datos más granulares, que incluyen información sobre cómo proceder con experimentos en grandes volúmenes de datos reales y cómo satisfacer las necesidades y desafíos de validación. Como mencioné, no estamos trabajando para cambiar AnaCredit per se, sino para comprender cómo aplicar xBRL-CSV a grandes conjuntos de datos para optimizar los informes.
Este es solo el comienzo de nuestro trabajo y pretendemos que sirva de base para una mayor experimentación. Algunos de nuestros próximos pasos podrían incluir agregar más tablas de AnaCredit al DPM, lo que también nos permitiría probar y analizar los controles de validación de AnaCredit existentes entre y dentro de las tablas, así como implementar y evaluar una validación compatible adicional. También nos gustaría agregar etiquetas en varios idiomas para ilustrar esta funcionalidad y, si es posible, experimentar con datos anónimos reales.
No hay duda de que las tendencias en los informes se están moviendo hacia la recopilación de mayores volúmenes de datos más granulares, pero estos datos no tienen sentido a menos que se puedan manejar y analizar de manera efectiva. Hasta ahora, xBRL-CSV parece ofrecer una solución eficiente y práctica para informes futuros, particularmente para reunir y dar sentido a la información de diversas jurisdicciones.